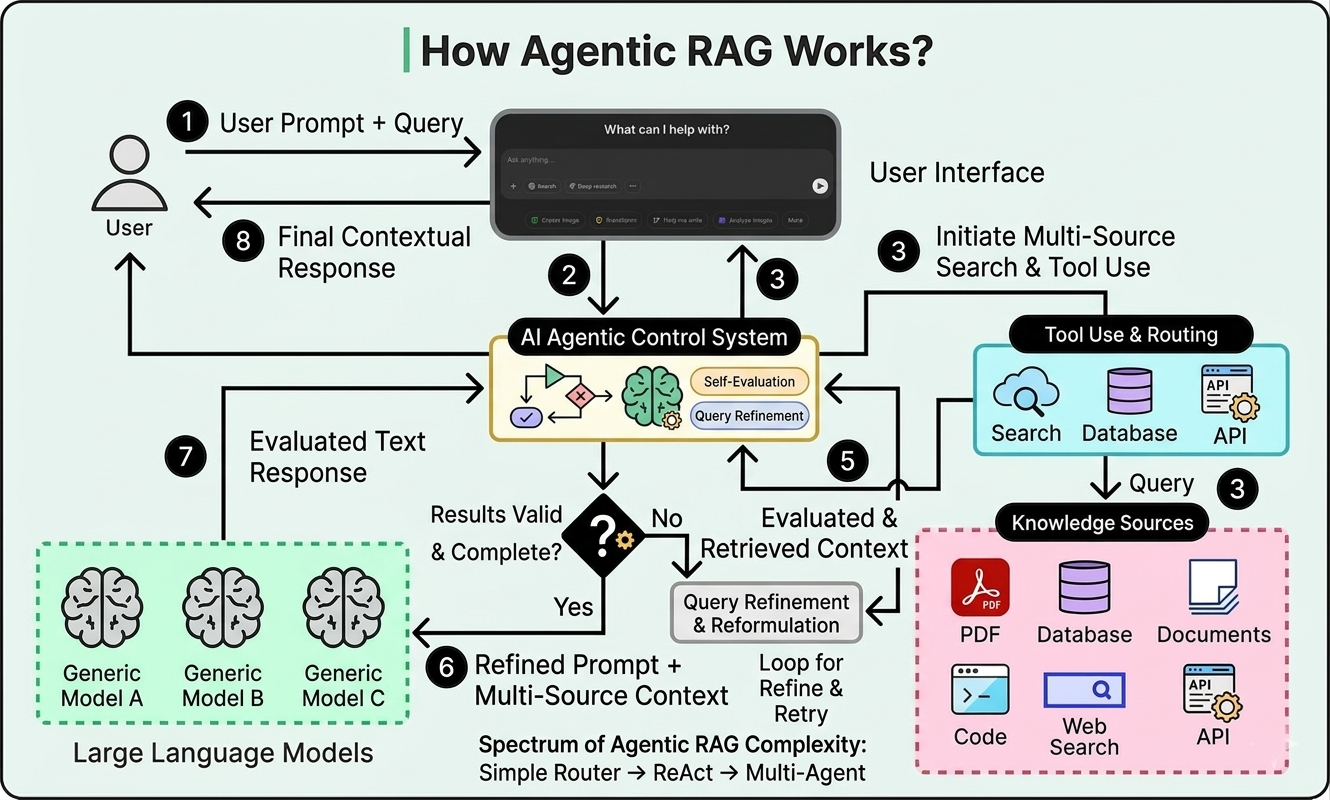
The main problem with standard Retrieval-Augmented Generation (RAG) systems isn’t the retrieval or the generation. It’s that nothing sits in the middle deciding whether the retrieval was actually good enough before the generation happens.
Standard RAG is a one-way pipeline: information flows from query to retrieval to response, with no checkpoints and no second chances. This works perfectly for simple questions with obvious answers.
However, the moment a query gets ambiguous, the answer is scattered across multiple documents, or the retrieval pulls back something that looks good but isn’t—standard RAG starts to break down.
Agentic RAG attempts to fix this problem by asking a single, transformative question: What if the system could pause and think before answering?
In this article, we will break down how Agentic RAG works, how it improves upon standard RAG pipelines, and the engineering trade-offs you must consider before implementing it.
The Flaw in the Pipeline: One Query, One Retrieval
To understand the value of Agentic RAG, we first need to look at where standard RAG falls short.
A standard RAG pipeline operates on a straightforward, linear flow: 1. A user asks a question. 2. The system converts the question into an embedding (a numerical representation capturing semantic meaning). 3. It searches a vector database to retrieve the top matching chunks of text. 4. Those chunks are passed to a Large Language Model (LLM) along with the original question to generate an answer.
This works beautifully for direct questions like, “What is our return policy?” against a well-organized knowledge base. But complex queries introduce three critical failure modes:
- Ambiguous Queries: If a user asks, “How do I handle taxes?” do they mean personal income, business, or nonprofit taxes? Standard RAG takes the query as-is, retrieves the highest similarity score, and hopes for the best.
- Scattered Evidence: An employee asking about remote work policies for contractors needs info from both the HR policy and the contractor agreement. Standard RAG retrieves from one pool and cannot check a second source.
- False Confidence: The system retrieves an outdated document that scores high on similarity but is factually wrong. The system has no mechanism to distinguish between “semantically relevant” and “actually correct.”
These failures share the same root cause: The system lacks reflection. It cannot evaluate its own retrieved results.
The Solution: Moving from Pipeline to Control Loop
Agentic RAG replaces the linear pipeline with a control loop by introducing AI agents.
At its core, an AI agent is a system that can perceive its environment, make decisions, and take independent actions to achieve goals. In the context of Agentic RAG, the agent is an LLM equipped with tools and decision-making capabilities. Instead of just generating text, it can run searches, query databases, or decide it needs more information before speaking.
Instead of retrieve-then-generate, the flow becomes: retrieve → evaluate → decide to answer (or try again) → retrieve differently if needed.
This introduces three massive capabilities:
1. Query Refinement (Solving Ambiguity)
Before searching, the agent can rewrite an ambiguous query into something highly specific. If the initial search yields results about personal income tax, but the context implies business tax, the agent can reframe the prompt and search again.
2. Tool Routing (Solving Scattered Evidence)
An agentic system can identify that a query requires multiple sources. It can route a financial question to a SQL database, a policy question to a document store, retrieve from both, and synthesize the results into a single, comprehensive answer.
3. Self-Evaluation (Solving False Confidence)
After retrieving data, the agent evaluates it. Is this relevant? Is it complete? Does it conflict with other data? If it pulls an outdated document, the evaluation step flags it, allowing the agent to search for a newer version or add a caveat to the final response.
The Trade-Offs: Is Agentic RAG Always Better?
While Agentic RAG sounds like a massive upgrade, every iteration of the control loop comes with costs. It should be an engineering decision, not a default choice.
- Latency: A standard RAG query takes 1-2 seconds. An agentic query with multiple loops could take 10+ seconds. For real-time chat applications, this is often unacceptable.
- Cost: Every loop is another LLM call consuming tokens. At scale, this can multiply your costs by 3x to 10x compared to standard RAG.
- Debugging Complexity: Standard RAG is deterministic. Agentic RAG introduces variability, making it harder to write tests, reproduce issues, or explain why the exact same question yielded a different process on Tuesday than it did on Monday.
- The Evaluator Paradox: The system’s ability to self-correct relies entirely on the LLM’s ability to judge relevance. A weak evaluator might reject perfectly good results, sending your system on an expensive wild goose chase.
Conclusion
Agentic RAG turns retrieval from a one-shot pipeline into a dynamic loop with decision points.
When evaluating whether to upgrade your AI architecture, ask yourself these three questions: 1. Is the system retrieving from the right source? 2. Can it evaluate whether the retrieved data is good enough? 3. Does it have the ability to try again if it fails?
If the answer to all three is "no," and your users are asking complex questions, it’s time to consider an agentic approach. But if your queries are simple and your knowledge base is clean, standard RAG is still the right tool for the job.
The shift from rigid pipelines to intelligent feedback loops isn't just the future of RAG—it's the future of AI development.